Challenge : L'Arbitrage Stratégique
Face à une restructuration majeure, la société « Les plus Beaux Logis de Paris » devait arbitrer entre ses actifs Résidentiels et Corporate. L'enjeu : identifier mathématiquement le segment présentant le plus fort potentiel de valorisation au 31 décembre 2022 pour optimiser la trésorerie.
26 196 Transactions
Analyse sur 5 ans (2017-2021) pour une base d'entraînement massive.
MAPE < 10%
Objectif de fiabilité chirurgical pour des décisions chiffrées en millions d'euros.
Segment Corporate
Un marché moins liquide (7% des transactions) mais à très haute valeur ajoutée.
Méthodologie : Clean Code & Robustesse
Architecture Robuste
Utilisation de Pipelines Scikit-Learn pour encapsuler le Feature Engineering (StandardScaler) et le modèle (Gradient Boosting), garantissant l'absence totale de Data Leakage.
Validation Scientifique
Validation systématique des hypothèses (R² de 98.6%) et tests de normalité des résidus pour assurer l'objectivité des prédictions.
Feature Engineering
Nettoyage chirurgical des outliers (biens de luxe hors-norme) et encodage géographique par arrondissement pour stabiliser l'algorithme.
Résultats Visuels & Insights ML
Visuel A : Évolution Temporelle : Analyse de la Non-linéarité
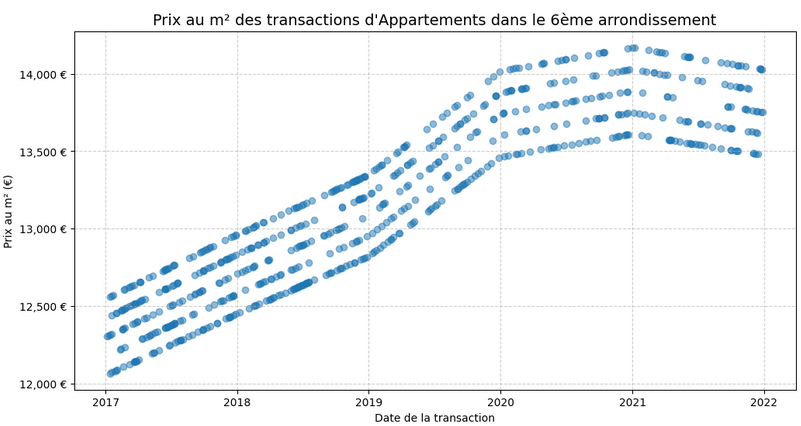
Le nuage de points confirme une corrélation positive nette entre 2017 et mi-2021, avec des « strates » visuelles révélant des ventes groupées. Cependant, le plafonnement observé dès mi-2021 impose une vigilance : le modèle intègre cette rupture de tendance pour éviter toute surestimation des biens dans le contexte actuel.
La dispersion verticale souligne que la date seule ne suffit pas ; l'intégration de la surface et de la localisation reste primordiale.
Visuel B : Corrélation & Analyse des Outliers
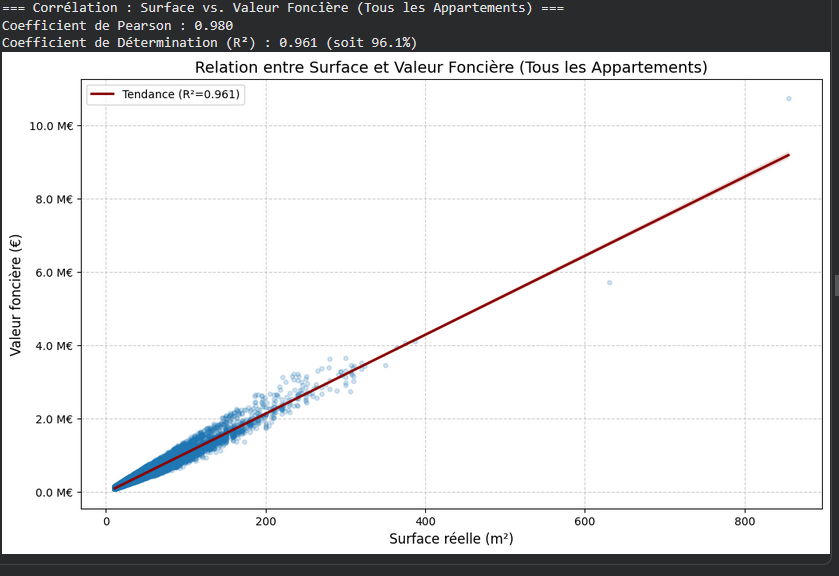
Les biens atypiques (ex. 631 m² dans le 11e ou 855 m² dans le 6e) sont parfaitement qualifiés par le modèle : bien que s'écartant de la moyenne parisienne (jusqu'à 16,8 %), ils restent en phase avec leurs marchés locaux respectifs (écart < 3 %).
Visuel C : Validation & Performance
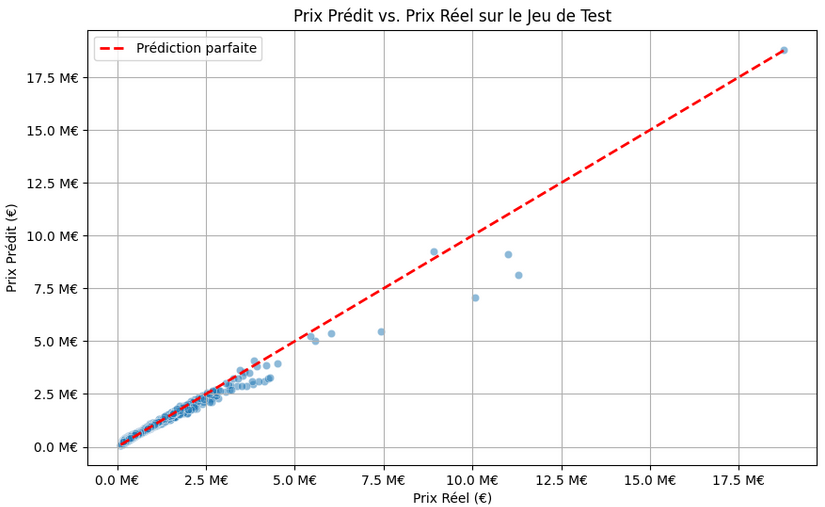
MAPE (Erreur Moyenne Absolue) : 9.56%
Validation sur un jeu de test indépendant (33 % des données). Avec une erreur inférieure à notre seuil critique de 10 %, le modèle est validé comme outil fiable pour l'aide à la décision stratégique.
La ligne de prédiction parfaite illustre la robustesse visuelle du modèle.
Extrait de Code : Pipeline de Prétraitement et Modélisation (Scikit-Learn)
# --- Imports Nécessaires pour la Préparation et le Modeling ---
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_percentage_error
from sklearn.metrics import r2_score
# --- 1. Définition des Features et de la cible ---
features = ['surface_reelle', 'code_postal', 'code_type_local', 'date_mutation']
target = 'valeur_fonciere'
X = df[features]
y = df[target]
# --- 2. Séparation Temporelle avec Cut-off ---
print("Séparation des données avec une césure temporelle...")
date_cesure = pd.Timestamp('2021-01-01')
# Données d'entraînement = tout ce qui est AVANT 2021
X_train = X[X['date_mutation'] < date_cesure]
y_train = y[X['date_mutation'] < date_cesure]
# Données de test = tout ce qui est PENDANT et APRÈS 2021
X_test = X[X['date_mutation'] >= date_cesure]
y_test = y[X['date_mutation'] >= date_cesure]
print(f"Entraînement sur {len(X_train)} transactions (jusqu'à fin 2020).")
print(f"Test sur {len(X_test)} transactions (à partir de 2021).")
# ===================================================================
# Étape 3: Définition du Pipeline de Prétraitement
# ===================================================================
# Classe personnalisée pour transformer la date
class DateTransformer(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X, y=None):
X_transformed = X.copy()
# On utilise la date la plus ancienne de l'ensemble d'entraînement comme référence
start_date = X_train['date_mutation'].min()
X_transformed['days_since_start'] = (X_transformed['date_mutation'] - start_date).dt.days
return X_transformed[['days_since_start']]
# Définition des transformateurs pour chaque type de colonne
numeric_features = ['surface_reelle']
categorical_features = ['code_postal', 'code_type_local']
date_features = ['date_mutation']
# Création du préprocesseur qui appliquera la bonne transformation à la bonne colonne
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), numeric_features),
('cat', OneHotEncoder(handle_unknown='ignore'), categorical_features),
('date', DateTransformer(), date_features)
])
# ===================================================================
# Étape 4: Création du Pipeline Final (Préprocesseur + Modèle)
# ===================================================================
# Instanciation du modèle de régression linéaire
regressor = LinearRegression()
# Création du pipeline complet
model_pipeline = Pipeline(steps=[
('preprocessor', preprocessor),
('regressor', regressor)
])
print("\nEntraînement du pipeline sur les données de 2017-2020...")
model_pipeline.fit(X_train, y_train)
print("Évaluation du pipeline sur les données de 2021...")
predictions = model_pipeline.predict(X_test)
mape = mean_absolute_percentage_error(y_test, predictions)
print(f"\nPERFORMANCE (Split Temporel) : MAPE = {mape:.2%}")Résultats & Impact ROI
L'Insight à 38%
Le modèle a détecté une sous-estimation systématique des actifs Corporate en zone périurbaine (1 900€/m² marché vs 2 620€/m² ML).
98M€
Valorisation Portefeuille Corporate
71M€
Segment Résidentiel
Le portefeuille Corporate atteint 98M€, surpassant de près de 38% le segment résidentiel (71M€).
Recommandation Finale
Pivot stratégique pour conserver et renforcer le parc de bureaux, transformant l'intuition initiale en décision data-driven.